引言
本文记录一次线上 GC 问题的排查过程与思路,希望对各位读者有所帮助。过程中也走了一些弯路,现在有时间沉淀下来思考并总结出来分享给大家,希望对大家今后排查线上 GC 问题有帮助。
背景
服务新功能发版一周后下午,突然收到 CMS GC 告警,导致单台节点被拉出,随后集群内每个节点先后都发生了一次 CMS GC,拉出后的节点垃圾回收后接入流量恢复正常(事后排查发现被重启了)。
告警信息如下(已脱敏):
多个节点几乎同时发生 GC 问题,且排查自然流量监控后发现并未有明显增高,基本可以确定是有 GC 问题的,需要解决。
排查过程
GC 日志排查
GC 问题首先排查的应该是 GC 日志,日志能能够清晰的判定发生 GC 的那一刻是什么导致的 GC,通过分析 GC 日志,能够清晰的得出 GC 哪一部分在出问题,如下是 GC 日志示例:
1 | 0.514: [GC (Allocation Failure) [PSYoungGen: 4445K->1386K(28672K)] 168285K->165234K(200704K), 0.0036830 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] |
如上 GC 日志能很明显发现导致 Full GC 的问题是:Full GC 之后,新生代内存没有变化,老年代内存使用从 165101K 降低到 165082K (几乎没有变化)。这个程序最后内存溢出了,因为没有可用的堆内存创建 70m 的大对象。
但是,生产环境总是有奇奇怪怪的问题,由于服务部署在 K8s 容器,且运维有对服务心跳检测,当程序触发 Full GC 时,整个系统 Stop World,连续多次心跳检测失败,则判定为当前节点可能出故障(硬件、网络、BUG 等等问题),则直接拉出当前节点,并立即重建,此时之前打印的 GC 日志都是在当前容器卷内,一旦重建,所有日志全部丢失,也就无法通过 GC 日志排查问题了。
JVM 监控埋点排查
上述 GC 日志丢失问题基本无解,发生 GC 则立即重建,除非人为干预,否则很难拿到当时的 GC 日志,且很难预知下次发生 GC 问题时间(如果能上报 GC 日子就不会有这样的问题,事后发现有,但是我没找到。。)。
此时,另一种办法就是通过 JVM 埋点监控来排查问题。企业应用都会配备完备的 JVM 监控看板,就是为了能清晰明了的看到“事故现场”,通过监控,可以清楚的看到 JVM 内部在时间线上是如何分配内存及回收内存的。
JVM 监控用于监控重要的 JVM 指标,包括堆内存、非堆内存、直接缓冲区、内存映射缓冲区、GC 累计信息、线程数等。
主要关注的核心指标如下:
- GC(垃圾收集)瞬时和累计详情
- FullGC 次数
- YoungGC 次数
- FullGC 耗时
- YoungGC 耗时
- 堆内存详情
- 堆内存总和
- 堆内存老年代字节数
- 堆内存年轻代 Survivor 区字节数
- 堆内存年轻代 Eden 区字节数
- 已提交内存字节数
- 元空间元空间字节数
- 非堆内存
- 非堆内存提交字节数
- 非堆内存初始字节数
- 非堆内存最大字节数
- 直接缓冲区
- DirectBuffer 总大小(字节)
- DirectBuffer 使用大小(字节)
- JVM 线程数
- 线程总数量
- 死锁线程数量
- 新建线程数量
- 阻塞线程数量
- 可运行线程数量
- 终结线程数量
- 限时等待线程数量
- 等待中线程数量
发生 GC 问题,重点关注的就是这几个指标,大致就能圈定 GC 问题了。
堆内存排查
首先查看堆内存,确认是否有内存溢出(指无法申请足够的内存导致),对内监控如下: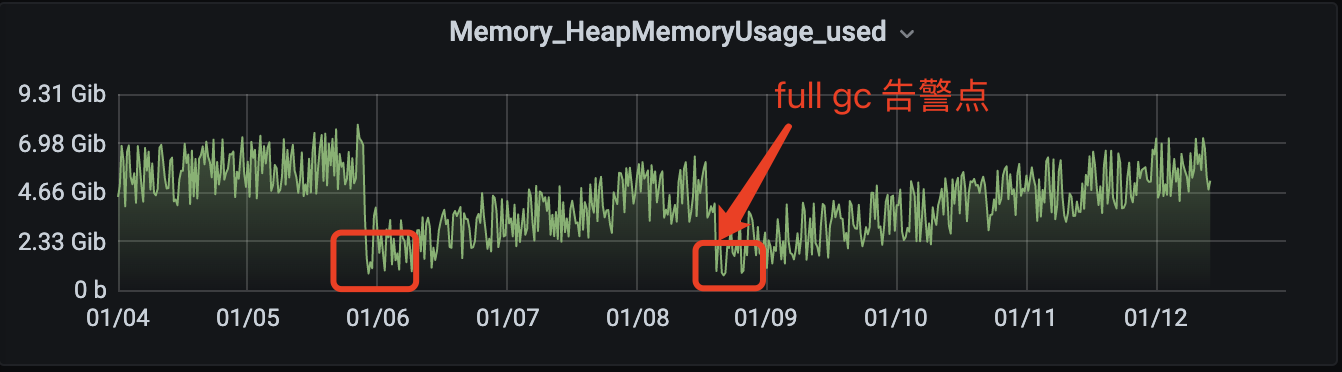
可以看到发生 Full GC 后,堆内存明显降低了很多,但是在未发生大量 Full GC 后也有内存回收到和全量 GC 同等位置,所以可以断定堆内存是可以正常回收的,不是导致大量 Full GC 的元凶。
非堆内存排查
非堆内存指 Metaspace 区域,监控埋点如下: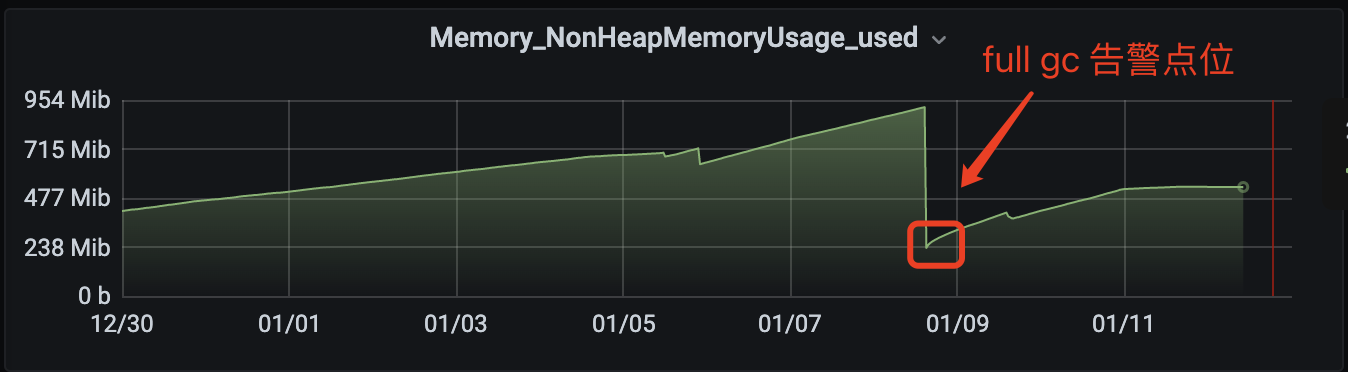
可以看到发生告警后,非堆内存瞬间回收很多(因为服务器被健康检查判定失效后重建,相当于重新启动,JVM 重新初始化),此处如果有 GC 排查经验的人一定能立即笃定,metaspace 是有问题的。
Metaspace 是用来干嘛的?JDK8 的到来,JVM 不再有 PermGen(永久代),但类的元数据信息(metadata)还在,只不过不再是存储在连续的堆空间上,而是移动到叫做 “Metaspace” 的本地内存(Native memory)中。
那么何时会加载类信息呢?
- 程序运行时:当运行 Java 程序时,该程序所需的类和方法。
- 类被引用时:当程序首次引用某个类时,加载该类。
- 反射:当使用反射 API 访问某个类时,加载该类。
- 动态代理:当使用动态代理创建代理对象时,加载该对象所需的类。
由上得出结论,如果一个服务内没有大量的反射或者动态代理等类加载需求时,讲道理,程序启动后,类的加载数量应该是波动很小的(不排除一些异常堆栈反射时也会加载类导致增加),但是如上监控显示,GC 后,metaspace 的内存使用量一直缓步增长,即程序内不停地制造“类”。
查看 JVM 加载类监控如下: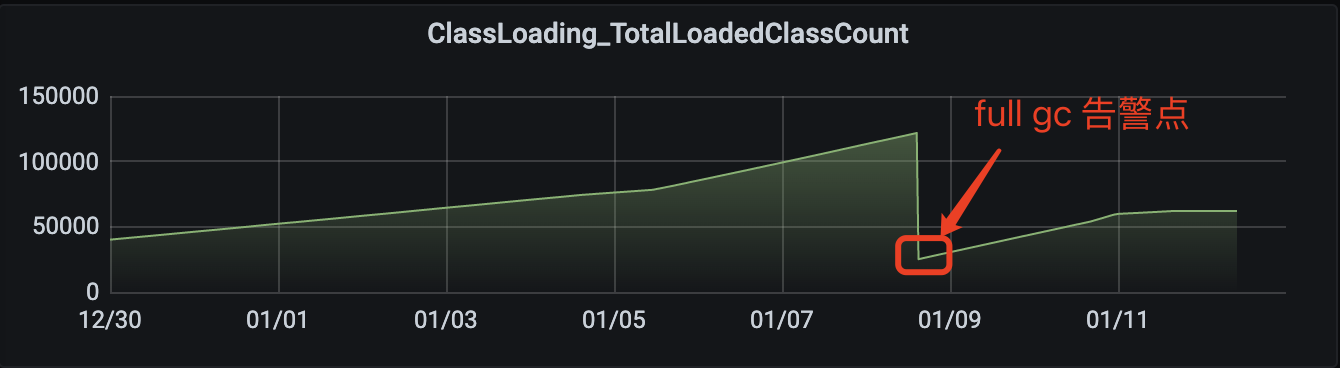
由上监控,确实是加载了大量的类,数量趋势和非堆使用量趋势吻合。
查看当前 JVM 设置的非堆内存大小如下: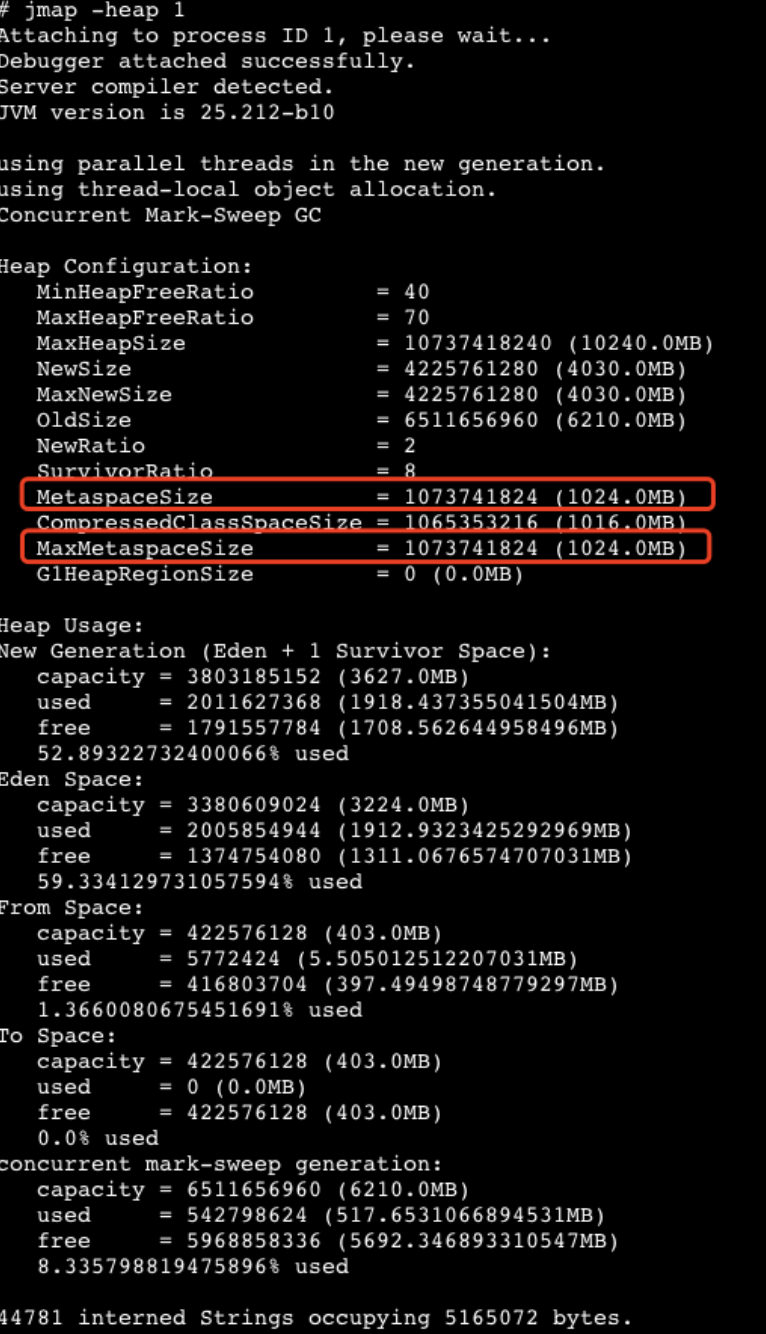
MetaspaceSize & MaxMetaspaceSize = 1024 M,由上面非堆内存使用监控得出,使用量已接近 1000 M,无法在分配足够的内存来加载类,最终导致发生 Full GC 问题。
程序代码排查
由上面排查得出的结论:程序内在大量的创建类导致非堆内存被打爆。结合当前服务内存在大量使用 Groovy 动态脚本功能,大概率应该是创建脚本出了问题,脚本创建动态类代码如下:
1 | public static GroovyObject buildGroovyObject(String script) { |
线上打开日志,确实证明了在不停的创建类。
脚本创建类导致堆内存被打爆,之间也是踩过坑的,针对同一个脚本(MD5 值相同),则会直接拿缓存,不会重复创建类,缓存 check 逻辑如下:
1 | public static GroovyObject buildScript(String scriptId, String script) { |
此处代码逻辑在之前的测试中都是反复验证过的,不会存在问题,即只有缓存 Key 出问题导致了类的重复加载。结合最近修改上线的逻辑,排查后发现,scriptId 存在重复的可能,导致不同脚本,相同 scriptId 不停重复加载(加载的频次 10 分钟更新一次,所以非堆使用缓慢上升)。
此处埋了一个小坑:加载的类使用 Map 存储的,即同一个 cacheKey 调用 Map.put() 方法,重复加载的类会被后面加载的类给替换掉,即之前加载的类已经不在被 Map 所“持有”,会被垃圾回收器回收掉,按理来说 Metaspace 不应该一直增长下去!?
提示:类加载与 Groovy 类加载、Metaspace 何时会被回收。
由于篇幅原因,本文就不在此处细究原因了,感兴趣的朋友自行 Google 或者关注一下我,后续我再专门开一章详解下原因。
总结
知其然知其所以然。
想要系统性地掌握 GC 问题处理方法,还是得了解 GC 的基础:基础概念、内存划分、分配对象、收集对象、收集器等。掌握常用的分析 GC 问题的工具,如 gceasy.io 在线 GC 日志分析工具,此处笔者参照了美团技术团队文章 Java 中 9 种常见的 CMS GC 问题分析与解决 收益匪浅,推荐大家阅读。
往期精彩
欢迎关注公众号:咕咕鸡技术专栏
个人技术博客:https://jifuwei.github.io/ >


